



About Client
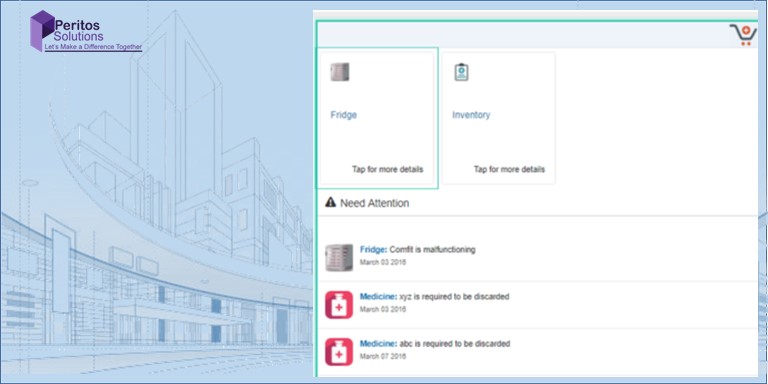
The world today is witnessing a growing trend in the use of technology in the health sector. This allowed us to assist our client, a pharmaceutical company in tracking medical devices and the quality of medicines on the go along with the inventory and transit status, and we supported them in AWS to IoT integration.
Project Background
In this case study, we achieved the following:
- How we implemented a small AWS IoT integration application with a toolkit to assure product quality, elevate the efficiency of medical devices, and raise alerts in case manual intervention is required
- Set up AWS for the application to manage the devices seamlessly
- Interaction with the device to fetch vital information
- Finally, creating a mobile application and using AWS IoT to monitor the devices
Scope & Requirement
We used the below solution components to create a responsive web application that gives a holistic view of all the devices connected to the system and information on their vital parameters.
Implementation
Technology and Architecture
Technology/ Services used
We used AWS services and helped them to setup below
- Cloud: AWS
- Organization setup: Control tower
- AWS SSO for authentication using existing AzureAD credentials
- Policies setup: Created AWS service control policies
- Templates created for using common AWS services
Security & Compliance:
- Tagging Policies
- AWS config for compliance checks
- NIST compliance
- Guardrails
- Security Hub
Network Architecture
- Site to Site VPN Architecture using Transit Gateway
- Distributed AWS Network Firewall
- Monitoring with Cloud Watch and VPC flow logs.
Backup and Recovery
Cloud systems and components used followed AWS’s well-Architected framework and the resources were all Multi-zone availability with uptime of 99.99% or more.
Cost Optimization
Alerts and notifications are configured in the AWS cost
Code Management, Deployment
Cloudformation scripts for creating stacksets and scripts for generating AWS services was handed over to the client
Challenges
- We encountered some issues as below:
- AWS setup and pricing were complicated to understand as it is based on usage and consumption, which was a difficult thing to assess at the start of the application
- Ensuring data privacy and security is of utmost importance in this case. Since devices can be hacked without much effort due to poor encryption and that could allow unauthorized access
- Impeccable quality assurance of the whole setup was to be achieved in this case of the pharmaceutical industry, which involves dealing with medicines are surgical instruments, so there was a need for honest sharing of information if anything was not going as expected.
- Understanding the client’s vision of how they needed the UI was challenging.
Support
- 1 month of extended support
- A template for Cloud formation stack to create more AWS resources using the available stacks
- Screen-sharing sessions with a demo of how the services and new workloads can be deployed.

About Client
Managing AWS Environment
Wine-Searcher is a web search engine that helps find the price and availability of any wine, whiskey, spirit, or beer worldwide. It has been in operation since 1999 and has offices in New Zealand and the UK. They provide an easy-to-use search engine, price comparison tools, an extensive database of wines and spirits, an encyclopedia, and news pages that aim to provide all “wine-finding” needs.
- https://www.wine-searcher.com/
- Location: New Zealand & UK
Project Background
As part of their plan to launch a full suite of digital products, Wine-Searcher chose AWS as their cloud environment. Strategic resource allocation and cost optimization are critical to ensure a cost-effective operation. Peritos helped as the reliable AWS partner on AWS Cost Explorer and AWS Budgets, like valuable tools for implementing ongoing discounted billing. Furthermore, leveraging reserved instances and spot instances and optimizing usage based on peak hours and demand patterns can result in significant cost savings. Experts from the Peritos team helped regularly monitor and fine-tune the AWS environment based on Winesearcher’s needs, allowing for continuous optimization while adhering to budgetary constraints and maintaining the required scalability and performance for their operations.
Scope & Requirement for Managing AWS Environment
In the 1st Phase of the AWS Environment Setup, implementation was discussed as follows:
- Manage Billing
- Value added services
- Handling Complex environments
- Multiple AWS invoices
- Cost Optimization
- Cloud security optimization
Implementation

Technology and Architecture of Managing AWS Environment
Furthermore, Read on the key components that defined the Architecture for managing the AWS Environment Setup for Wine-Searcher
Technology/ Services used
We used AWS services and helped them to setup below
- Cloud: AWS
- Organization setup: Control tower
- AWS SSO for authentication using existing AzureAD credentials
- Policies setup: Created AWS service control policies
- Templates created for using common AWS services
Security & Compliance:
- Tagging Policies
- AWS config for compliance checks
- NIST compliance
- Guardrails
- Security Hub
Network Architecture
- Site to Site VPN Architecture using Transit Gateway
- Distributed AWS Network Firewall
- Monitoring with Cloud Watch and VPC flow logs.
Backup and Recovery
- Cloud systems and components used followed AWS’s well-architected framework, and the resources were all Multi-zone availability with uptime of 99.99% or more.
Cost Optimization
- Alerts and notifications are configured in the AWS cost
Code Management, Deployment
Cloudformation scripts for creating stack sets and scripts for generating AWS services were handed over to the client
Challenges in Implementing Managing AWS Environment
- Collate all accounts together
- Understand and agree on how the account would be managed under the distribution model
Support
- One month of extended support
- A template for Cloud formation stack to create more AWS resources using the available stacks
- Screen-sharing sessions with demos of how the services and new workloads can be deployed.
Next Phase
We are now looking at the next phase of the project, which involves:
- Implementing a control tower for the client.
About Client
AWS Compute & High-performance Computing
Tonkin + Taylor is New Zealand’s leading environment and engineering consultancy with offices located globally. They shape interfaces between people and the environment, which includes earth, water, and air. Additionally, They have won awards like the Beaton Client Choice Award for Best Provider to Government and Community-2022 and the IPWEA Award for Excellence in Water Projects for the Papakura Water Treatment Plan- 2021.
- https://www.tonkintaylor.co.nz/
- Location: New Zealand
Project Background
Tonkin + Taylor were embarking on launching a full suite of digital products and zeroed upon AWS as their choice for a cloud environment. Moreover, They wanted to accelerate their digital transformation and add more excellent business value through AWS Development Environment best practices. To achieve all this, we needed to configure AWS Compute & High-Performance Computing, following best practices and meeting compliance standards, which can serve as a foundation for implementing more applications. Furthermore, The AWS Lake House is a central data hub that consolidates data from various sources and caters to all applications and users. It can quickly identify and integrate any data source. The data goes through a meticulous 3-stage refining process: Landing, Raw, and Transformed. Additionally, After the refinement process, it is added to the data catalog and is readily available for consumption through a relational database.
Scope & Requirement for AWS Compute & High Performance Computing
The 1st Phase of the AWS Environment Setup discussed implementation as follows:
- Implement Data Lakehouse on AWS
Implementation
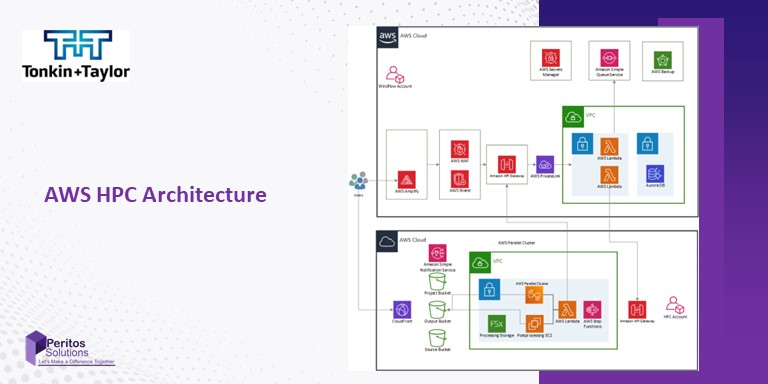
Technology and Architecture of AWS Compute & High Performance Computing
The 1st Phase of the AWS Environment Setup discussed implementation as follows:
Technology/ Services used
We used AWS services and helped them to setup below
- Cloud: AWS
- Organization setup: Control tower
- AWS SSO for authentication using existing AzureAD credentials
- Policies setup: Created AWS service control policies
- Templates created for using common AWS services
Security & Compliance:
- Tagging Policies
- AWS config for compliance checks
- NIST compliance
- Guardrails
- Security Hub
Network Architecture
- Site to Site VPN Architecture using Transit Gateway
- Distributed AWS Network Firewall
- Monitoring with Cloud Watch and VPC flow logs.
Backup and Recovery
Cloud systems and components used followed AWS’s well-Architected framework and the resources were all Multi-zone availability with uptime of 99.99% or more.
Cost Optimization
Alerts and notifications are configured in the AWS cost
Code Management, Deployment
Cloudformation scripts for creating stacksets and scripts for generating AWS services was handed over to the client
AWS Compute & High Performance Computing Challenges & Solutions
- Diverse data sources- Data Analytics and cleaning up and integration patterns to pull data from different data sources
- On-premise data connection to data lake migration- Site-to-site Secure AWS connection was implemented
- Templatized format for creating pipelines- Created scripts of specific format, Deployment scripts, and CI CD scripts
Support
Providing ongoing support as we are a dedicated development partner for the client
Next Phase
We are now looking at the next phase of the project, which involves:
- API and file-based data sources to be added
- Process data to be used in different applications for ingesting in other applications
About Client
AWS Control Tower Setup
Wine-Searcher is a web search engine that helps find the price and availability of wine, whiskey, spirits, and beer worldwide.
It has been operating since 1999, with offices in New Zealand and the UK. The platform offers search tools, price comparison,
an extensive database, an encyclopedia, and news content to support all wine-finding needs.
- https://www.wine-searcher.com/
- Location: New Zealand & UK
Project Background
Peritos led the AWS Control Tower setup for Wine-Searcher, optimizing their cloud infrastructure.
The implementation streamlined governance, improved compliance, and enabled secure scalability.
Multiple accounts were consolidated and managed using AWS Organizations within Control Tower.
The environment was configured to meet specific business needs, ensuring efficient resource management
and cost control. With built-in automation and governance, Wine-Searcher gained a strong foundation
for future growth while focusing on innovation and user experience.
Scope & Requirement for AWS Control Tower Setup
- Prerequisite: Automated pre-launch checks for the management account
- Step 1: Create shared account email addresses
- Define expectations for landing zone configuration
- Step 2: Configure and launch the landing zone
- Step 3: Review and finalize the landing zone setup
Implementation
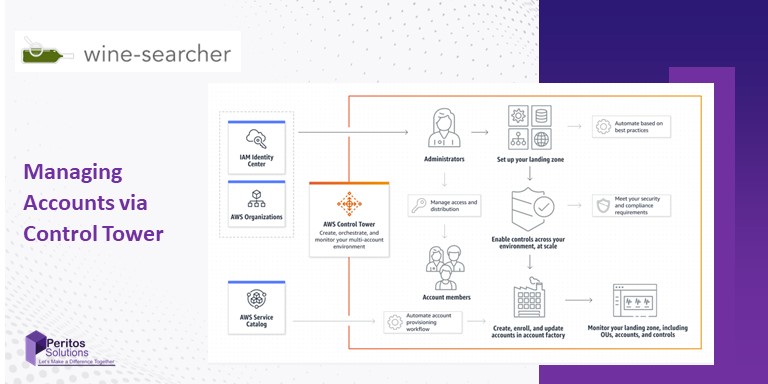
Technology and Architecture of AWS Control Tower Setup
- Read about the key components defining the AWS Control Tower architecture for Wine-Searcher
Technology / Services Used
- We used AWS services to set up the following:
- Cloud: AWS
- Organization setup: Control Tower
- AWS SSO integrated with Azure AD credentials
- Policies setup: AWS Service Control Policies (SCPs)
- Templates created for common AWS services
Security & Compliance
- Tagging policies
- AWS Config for compliance checks
- NIST compliance
- Guardrails
- Security Hub
Network Architecture
- Site-to-site VPN using Transit Gateway
- Distributed AWS Network Firewall
- Monitoring with CloudWatch and VPC Flow Logs
Backup and Recovery
- Infrastructure follows AWS Well-Architected Framework with multi-zone availability and 99.99% uptime
Cost Optimization
Alerts and notifications are configured to monitor AWS costs and prevent budget overruns.
Code Management & Deployment
CloudFormation scripts for stack sets and AWS service provisioning were handed over to the client.
Challenges in Implementing AWS Control Tower Setup
- Landing Zone Drift
- Role Drift
- Security Hub Control Drift
- Trusted Access disabled
Support
- 1 month extended support
- A template for Cloud formation stack to create more AWS resources using the available stacks
- In addition, Screen sharing sessions with demo of how the services and new workloads can be deployed.
About Client
1Place is a technology-driven organization focused on leveraging data to enhance decision-making, reporting, and operational intelligence. The company manages a growing data ecosystem comprising multiple data sources, analytics tools, and business applications. AWS offers glue as a fully managed etl service
To address scalability challenges and improve data automation, 1Place collaborated with Peritos Solutions, an AWS Advanced Consulting Partner, to design and implement a serverless data platform using AWS Glue. The goal was to replace manual data workflows with a secure, automated ETL framework that ensures accuracy, consistency, and governance.
Project Background – Data Modernization through AWS Glue ETL service
1Place data operations were previously dependent on traditional ETL tools that lacked automation and flexibility. These manual processes caused data silos, inconsistent data quality, and delayed reporting.
Peritos Solutions proposed an AWS Glue-based serverless ETL framework to transform 1Place data landscape. The solution automated schema detection, data cataloging, and transformation pipelines while ensuring end-to-end visibility through AWS CloudWatch and centralized governance.
This transformation allowed 1Place to manage large-scale data workloads with minimal operational overhead while maintaining compliance, traceability, and cost efficiency.

Objectives of the Engagement
- Establish a serverless, automated data integration framework using AWS Glue ETL service
- Replace legacy ETL pipelines with scalable and efficient Glue jobs
- Implement centralized metadata management using AWS Glue Data Catalog.
- Enable cross-service data integration with S3, RDS, and Redshift.
- Ensure security, governance, and compliance through IAM, encryption, and monitoring.
Scope & Requirements
Scope
The project’s scope included the design, deployment, and optimization of AWS Glue components to enable seamless data flow across 1Place AWS environment.
Key deliverables included:
- AWS Glue Crawlers for automated schema detection.
- Glue Jobs for data transformation and enrichment.
- Glue Workflows for end-to-end orchestration.
- Centralized Data Catalog for metadata governance.
- CloudWatch monitoring and alerting integration.
Requirements
Functional:
- Automated ETL pipeline creation and scheduling.
- Dynamic schema detection and updates.
- Integration with Amazon Redshift and Athena for analytics.Non-Functional:
- Serverless architecture for scalability.
- Secure access control with IAM.
- Centralized monitoring and auditing.
- Cost efficiency and fault tolerance.

AWS Glue ETL service Implementation support for Pipeline Automation
Solution Overview -AWS Glue ETL service
Business Problem Addressed
1Place existing ETL infrastructure was time-intensive and not scalable. Manual intervention led to delays, higher costs, and inconsistent data quality.
Proposed AWS Glue-Based Solution
Peritos Solutions implemented an end-to-end AWS Glue solution integrating multiple data sources and automating data transformation and cataloging. Using Glue Crawlers, Jobs, and Workflows, the entire ETL process became event-driven, reducing human intervention and operational latency.
Key Benefits
- Serverless data integration with zero infrastructure management.
- Automated data discovery and schema management.
- Faster and more reliable data transformation pipelines.
- Improved data governance through centralized metadata.
- Seamless analytics enablement through Athena and QuickSight integration.
Implementation -AWS Glue ETL service
Architecture Overview
The architecture consisted of:
- Data Sources: S3, RDS, and on-premises data via secure connectors.
- ETL Layer: AWS Glue Crawlers, Jobs, and Workflows.
- Data Catalog: Centralized schema and metadata management.
- Analytics Layer: Athena and QuickSight for visualization.
- Monitoring & Logging: CloudWatch for logs, metrics, and alerts.
Technology Stack
- AWS Services: Glue, S3, RDS, Redshift, CloudWatch, Lambda, Secrets Manager, IAM.
- Security: KMS encryption, MFA-enabled IAM roles, and cross-account logging.
- Automation: CI/CD pipelines with AWS CodePipeline and CodeBuild.
AWS Glue Components Implemented
- Glue Crawlers: Automated schema discovery for S3 and RDS datasets.
- Glue Jobs: ETL scripts built using PySpark to clean, normalize, and enrich data.
- Glue Workflows: Orchestration for dependency-based execution.
- Data Catalog: Managed metadata, table schemas, and data lineage.
- Triggers: Event-driven execution using CloudWatch and EventBridge.
Security and Compliance
- IAM policies applied with least privilege.
- Glue roles restricted to authorized services only.
- KMS encryption applied for data at rest and in transit.
- CloudTrail enabled for audit trails and compliance verification.
Runbook and Troubleshooting Scenarios
Routine Operational Tasks
- Daily monitoring of Glue job metrics and DPU utilization.
- Reviewing failed job logs and rerunning based on SLA thresholds.
- Verifying Data Catalog updates and schema integrity.
- Checking Glue job triggers and workflow dependencies.
Common Troubleshooting Scenarios
- Job Failures Due to Schema Drift: Re-run Glue Crawler, refresh Data Catalog, and update ETL script mapping.
- Performance Degradation: Tune Spark configurations and increase DPU allocation.
- Connection Errors: Validate IAM permissions, VPC configurations, and network paths.
- Data Quality Issues: Use Glue dynamic frames and AWS Deequ for validation.

AWS Glue ETL service Implementation support
Deployment Readiness Checklist
Testing
- Unit, integration, and system testing of all Glue jobs.
- Validation of schema mapping, data accuracy, and job success rates.
Automation
- CI/CD pipelines integrated for job versioning and automated deployment.
- Security scans embedded in build pipelines.
Documentation
- Deployment runbook, rollback plan, and configuration details maintained.
Monitoring & Validation
- Glue job metrics and alerts verified in CloudWatch.
- Post-deployment validation ensured job stability.
Evidence: Deployment logs, Glue job screenshots, and automation reports attached to project documentation.
Cost Optimization and Performance Tuning
- Used Glue 3.0 for faster job performance and improved scaling.
- Optimized DPU allocation and job parallelism.
- Leveraged job bookmarks for incremental data loads.
- Enabled data partitioning in S3 for query efficiency.
- Monitored spend through AWS Cost Explorer and adjusted scheduling.
Challenges and Resolutions
| Challenge | Resolution |
| Schema evolution from multiple data sources | Automated schema updates via Glue Crawlers |
| Long-running ETL jobs | Spark job optimization and dynamic partitioning |
| Data duplication in catalogs | Automated Data Catalog cleanup and versioning |
| Integration with legacy databases | Implemented secure JDBC connections and Glue connections |
| Monitoring job failures | Integrated CloudWatch alerts with email/SNS notifications |
Project Completion – AWS Glue ETL service
Deliverables
- AWS Glue Data Catalog, Crawlers, Jobs, and Workflows.
- CloudWatch dashboards for Glue performance monitoring.
- Operational Runbook and Troubleshooting Guide.
- Deployment Readiness Checklist and Evidence Reports.
- CI/CD pipelines for Glue job automation.
Support
Post-implementation support for two months, including 20 hours/month of operational support, bug fixes, and performance optimization.
Next Phase
- Integrate with AWS Lake Formation for enhanced data governance.
- Implement data lineage tracking and metadata versioning.
- Expand to real-time streaming ETL using AWS Glue and Kinesis.
- Develop monitoring dashboards using QuickSight for Glue job analytics.
- Conduct quarterly optimization reviews for cost and performance improvements.

AWS Glue ETL service Implementation support
Reference Links AWS Glue ETL service
https://docs.aws.amazon.com/prescriptive-guidance/latest/patterns/build-an-etl-service-pipeline-to-load-data-incrementally-from-amazon-s3-to-amazon-redshift-using-aws-glue.html
Read more about Glue
https://aws.amazon.com/glue/
Read more here about our services
AWS Glue Services
- https://www.peritossolutions.com/services/aws-glue-serverless-data-integration/
AWS consulting Services
- https://www.peritossolutions.com/aws-consulting



 Recent Home
Recent Home
 Recent Home
Recent Home
 Recent Home
Recent Home
 Recent Home
Recent Home
 Recent Home
Recent Home

Peritos is a team of highly skilled developers, technical experts, and delivery managers. We’ve been very impressed with their commitment. Their developers and delivery managers have conducted themselves with professionalism and diligence at all times, and the quality of the work they have performed has been excellent. Many times, they proposed better solutions, which resulted in better and faster products. Peritos is a reliable AWS Partner. You can trust and be satisfied.
“We are very happy with the results of this major IT project with Peritos Solutions. Their staff gained a good knowledge of our business and processes. They were able to work with many of our diverse team members and launch Business Central ERP on time and on budget according to our requirements. We will be using them again for future projects and additional development actions. Thank you!”
The project was completed on time and as per the agreed budget. The communication was excellent, as was the dedication to quickly turning around the required report development. The overall experience was good, and I would definitely work with the Peritos Team again.
 Recent Home
Recent Home
 Recent Home
Recent Home
 Recent Home
Recent Home
 Recent Home
Recent Home




