



About Ektos Health
Ektos Health was built by Peritos Solutions in response to a clear gap in the Indian healthcare market: hospitals and diagnostic centres were running on fragmented systems — paper-based appointment registers, disconnected lab software, manually typed prescriptions, and spreadsheet billing. The result was errors, delays, compliance risk, and frustrated staff.
The vision was to build a single, cloud-based HMIS that any hospital — from a small diagnostic centre to a multi-specialty hospital — could deploy without heavy IT infrastructure, get up and running quickly, and be confident it met India’s digital health standards from day one.
Ektos Health is proudly developed by Peritos Solutions and is available at ektos-health.com. It is deployed for diagnostic centres, polyclinics, and hospitals across India.
The Problem
- Appointment booking managed on paper or basic spreadsheets — no real-time visibility of doctor availability or patient queue
- Lab test requests, sample tracking, and report delivery disconnected from patient records — requiring manual re-entry
- Prescription generation required doctors to type everything manually — time-consuming, error-prone, and inconsistent
- No intelligent support for diagnosis — doctors working without access to the patient’s full history and previous diagnoses at the point of consultation
- IPD admission and bed management done manually — no real-time bed availability visibility
- Billing disconnected from clinical services — charges for lab tests, consultations, and procedures reconciled separately
- No compliance infrastructure for ABDM or NABH — hospitals at risk of failing accreditation requirements
- Patient health records not linked to national health IDs (ABHA/Aadhaar) — no interoperability with India’s digital health ecosystem
Scope & Feature List
|
Module 1 — Appointment Booking & Management |
|
A centralized, real-time appointment management system for walk-in and online bookings:
|
|
Module 2 — Patient Management |
|
Complete end-to-end patient record management — from first registration to ongoing care:
|
|
Module 3 — Laboratory Management (Diagnostic Centre) |
|
End-to-end lab workflow management — from test assignment to report delivery — purpose-built for diagnostic centres:
|
|
Module 4 — AI Prescription Generation & Clinical Intelligence |
|
The AI layer is the most powerful differentiator in Ektos Health — enabling doctors to generate accurate, formatted prescriptions in under a minute using voice or text, with AI-assisted diagnosis support: Voice-to-Text Prescription Dictation
AI-Generated Diagnosis Suggestions
AI Prescription PDF Generation
|
|
Module 5 — Admission & Discharge (IPD) |
|
Full inpatient lifecycle management — from bed allocation on admission to discharge summary generation:
|
|
Module 6 — Billing Management |
|
Integrated, transparent billing across all hospital services — from OPD consultations to lab tests and inpatient stays:
|
|
Module 7 — Settings, Master Data & System Configuration |
|
Full control over how Ektos Health operates within your institution:
|
ABDM & NABH Compliance
Ektos Health is built from the ground up to meet India’s national digital health standards — not as an afterthought, but as a core architectural requirement:
|
ABDM Compliance |
Full integration with Ayushman Bharat Digital Mission — ABHA creation, verification, and health record linkage built into appointment, lab, and prescription workflows |
|
ABHA Integration |
Patients can create a new ABHA (Ayushman Bharat Health Account) or link an existing one at registration — enabling secure nationwide health record interoperability |
|
Aadhaar Verification |
Aadhaar-based patient identity verification supported at registration and appointment booking |
|
Digital Prescriptions |
AI-generated prescription PDFs comply with ABDM digital prescription standards — shareable via ABHA |
|
NABH Standards |
Workflow design, documentation requirements, consent management, and audit trails align with NABH accreditation criteria |
|
Audit Trails |
All clinical and administrative actions logged with user, timestamp, and action type — supporting NABH audit requirements |
|
Data Security |
Patient health data encrypted at rest and in transit — role-based access prevents unauthorised data exposure |
|
Compliance Readiness |
90% compliance readiness score across ABDM/NABH requirements — hospitals go live already meeting accreditation benchmarks |
Technology & Architecture
Ektos Health is a cloud-native application built on modern web technologies, deployed on scalable cloud infrastructure:
|
Frontend |
React.js — fast, responsive, mobile-compatible web interface — works on desktop, tablet, and mobile without a separate app |
|
Backend |
Node.js / Python REST APIs — microservice architecture for each module (appointments, lab, billing, AI) |
|
Cloud |
Cloud-hosted — scalable, high-availability infrastructure with 24/7 uptime monitoring |
|
Database |
Secure relational database with full patient record history, audit logs, and real-time updates |
|
AI Engine |
GPT-4 integration for diagnosis suggestions and prescription generation — custom prompt engineering for clinical context |
|
Voice-to-Text |
Speech recognition API with medical vocabulary training — dictation converted to structured prescription text |
|
PDF Engine |
Automated prescription and lab report PDF generation — templated, branded, and configurable per department |
|
ABDM API |
Official ABDM API integration — ABHA creation, verification, and health record exchange |
|
Notifications |
SMS and email notification engine — appointment reminders, lab result alerts, billing confirmations |
|
Security |
Role-based access control, encrypted data transmission, session management, and full audit logging |
AI Features — How They Work
|
AI Feature |
How It Works |
Clinical Benefit |
|
Voice-to-Text Prescription |
Doctor speaks the prescription aloud. Speech recognition converts dictation to structured text — drug names, dosages, instructions — in real time. Doctor reviews and confirms before saving. |
Consultation time reduced significantly. Doctor maintains eye contact with patient rather than typing. Reduces transcription errors. |
|
AI Diagnosis Suggestion |
Doctor enters chief complaint and clinical notes. AI analyses these against the patient’s stored diagnosis history and symptom patterns to suggest probable diagnoses ranked by likelihood. |
Supports junior doctors with differential diagnosis. Reduces diagnostic oversight. Highlights conditions to rule out. Improves clinical decision quality. |
|
AI Prescription PDF |
Once diagnosis and treatment are confirmed, the system auto-generates a formatted, branded prescription PDF including patient details, diagnosis, medications with dosage and frequency, and follow-up date. |
Professional, legible, legally compliant prescriptions every time. Stored against patient record. Shareable via ABHA. No formatting overhead for doctor. |
|
Previous Diagnosis Context |
AI accesses the patient’s full longitudinal history — all previous diagnoses, medications, allergies, and test results — as context when generating suggestions for the current visit. |
Prevents prescribing contraindicated medications. Highlights recurring conditions. Improves continuity of care across multiple visits and doctors. |
Implementation Approach
Ektos Health is deployed as a cloud SaaS product. New hospitals and diagnostic centres can be onboarded and live within days:
|
Day 1–2 — Setup |
Hospital profile, branding, departments, doctors, and billing items configured in Master Data and Settings. User roles and access levels assigned. |
|
Day 2–3 — Integration |
ABDM/ABHA API connection configured. SMS/email notification templates set up. Diagnostic machine connectivity tested where applicable. |
|
Day 3–4 — Data Entry |
Existing patient records migrated or entered. Lab test catalogue configured. Room and bed categories set up for IPD centres. |
|
Day 4–5 — Training |
Staff training on appointment, lab, billing, and prescription workflows. Doctors trained on voice-to-text and AI diagnosis features. |
|
Day 5 — Go-Live |
Live patient appointments and consultations begin. Peritos Solutions provides hypercare support for the first two weeks post-launch. |
|
Ongoing |
24/7 cloud support. Feature updates deployed automatically. AI model improves with usage. ABDM regulatory updates applied centrally. |
Client Testimonials
|
“Ektos Health has significantly streamlined our operations and improved efficiency across our healthcare workflows. The platform is intuitive, reliable, and backed by a highly responsive team at Peritos Solutions.” — Akanksha Niranjan, Director, Ekanshi Solutions, Lucknow |
|
“The platform has simplified our day-to-day clinic management, from patient records to reporting. It has reduced manual work and improved overall efficiency. The support team is proactive and always available when needed.” — Dr. Ramnath Mishra, Clinic, Bhubaneswar |
|
“Ektos Health has transformed how we manage patient records and hospital operations. The system is easy to use, secure, and provides quick access to critical information, enabling us to deliver better patient care.” — Dr. Anil Chowdhary, Lal Kothi Hospital, Jaipur |
Key Benefits
- Single integrated platform replacing 4–6 disconnected systems — appointments, lab, prescriptions, billing, IPD, and patient records all in one
- AI-powered prescription generation reduces doctor consultation time by 40–60% — voice dictation eliminates manual typing
- AI diagnosis suggestions based on chief complaint and full patient history — improves clinical decision quality, especially for junior doctors
- Automated PDF prescription and lab report generation — professional, branded, legally compliant output every time
- Real-time bed management and IPD visibility — no more manual bed registers or phone calls to check availability
- Full ABDM compliance from day one — ABHA integration, digital prescriptions, and interoperability with India’s national health ecosystem
- NABH-aligned workflows, consent management, and audit trails — reduces accreditation preparation effort significantly
- Cloud-based deployment — no on-premise servers required, accessible from any device, 24/7 uptime
- Configurable without IT support — branding, templates, user roles, and settings managed by hospital administrators
- Scalable from a single diagnostic centre to a multi-specialty hospital — same platform, different configuration
Ready to Transform Your Hospital’s Operations?
Book a free demo of Ektos Health HMIS — and see AI prescription generation, voice-to-text, lab management, and ABDM compliance in action. Deployed and live within days.
info@ektos-health.com | ektos-health.com | Peritos Solutions | www.peritossolutions.com
About the Client
Bayleys Real Estate is New Zealand’s largest full-service real estate agency, operating across residential, commercial, rural, and property management services across New Zealand and Australia. With over 150 property management agents generating 1,800 to 2,000 rental appraisals per month, the manual documentation workload was significant, inconsistent across regions, and a major drain on agent productivity.
The leadership team — including the National Director and Financial Director — identified AI-driven automation as the strategic priority, with a clear mandate: cut appraisal time, improve consistency and accuracy, and free agents to focus on client relationships rather than documentation.
Project Background
Bayleys was already running a modern AWS-hosted property search web application built by Peritos Solutions — giving agents a cloud-based way to search and manage property records from any device. The next phase was to add AI intelligence on top of that foundation.
Each rental appraisal required an agent to manually research comparable properties, write a property description, calculate a market rent range, pull together agent branding and contact details, and format everything into a professional PDF. This 30 to 45 minute process, repeated thousands of times per month, was the single biggest time drain in the property management workflow.
Peritos Solutions was engaged to design and build the AI upgrade: automating the appraisal document, training a mathematical valuation model on historical data, deploying an AI copywriting engine for property descriptions, and building the AskKen AI chatbot for on-demand knowledge access.
Requirements
- Generate a complete, professional, branded rental appraisal report in under one minute — from a single property address entry
- AI-generated property description — trained on thousands of historical Bayleys appraisals to match the tone and style of an experienced property manager
- EMV (Estimated Market Rent) calculated by a machine learning model trained on historical sales and rental data — accuracy within ±3% of experienced agent assessment
- Property attributes (bedrooms, bathrooms, floor area, carparks) automatically retrieved via CoreLogic API
- Property listing image automatically pulled via Bayleys API where the property is currently listed for sale
- Agent profile photo, name, contact details, and office auto-populated via Office 365 Single Sign-On
- School zones and local amenities automatically identified from property address
- Support for multiple property types — house, apartment, unit, minor dwelling, home and income
- Manual entry flow for new-build and off-plan properties not yet in CoreLogic or Bayleys systems
- AskKen AI chatbot — zero-training, conversational interface covering legislation, tribunal cases, market data, maintenance costs, yield calculations, and suburb intelligence
- RAG architecture grounding all AI responses in controlled Bayleys proprietary data — not the open internet
Scope & Feature List
|
Module 1 — Automated Rental Appraisal Report |
|
A property manager enters or confirms the property address. The system generates a complete, professionally formatted, Bayleys-branded rental appraisal report automatically:
|
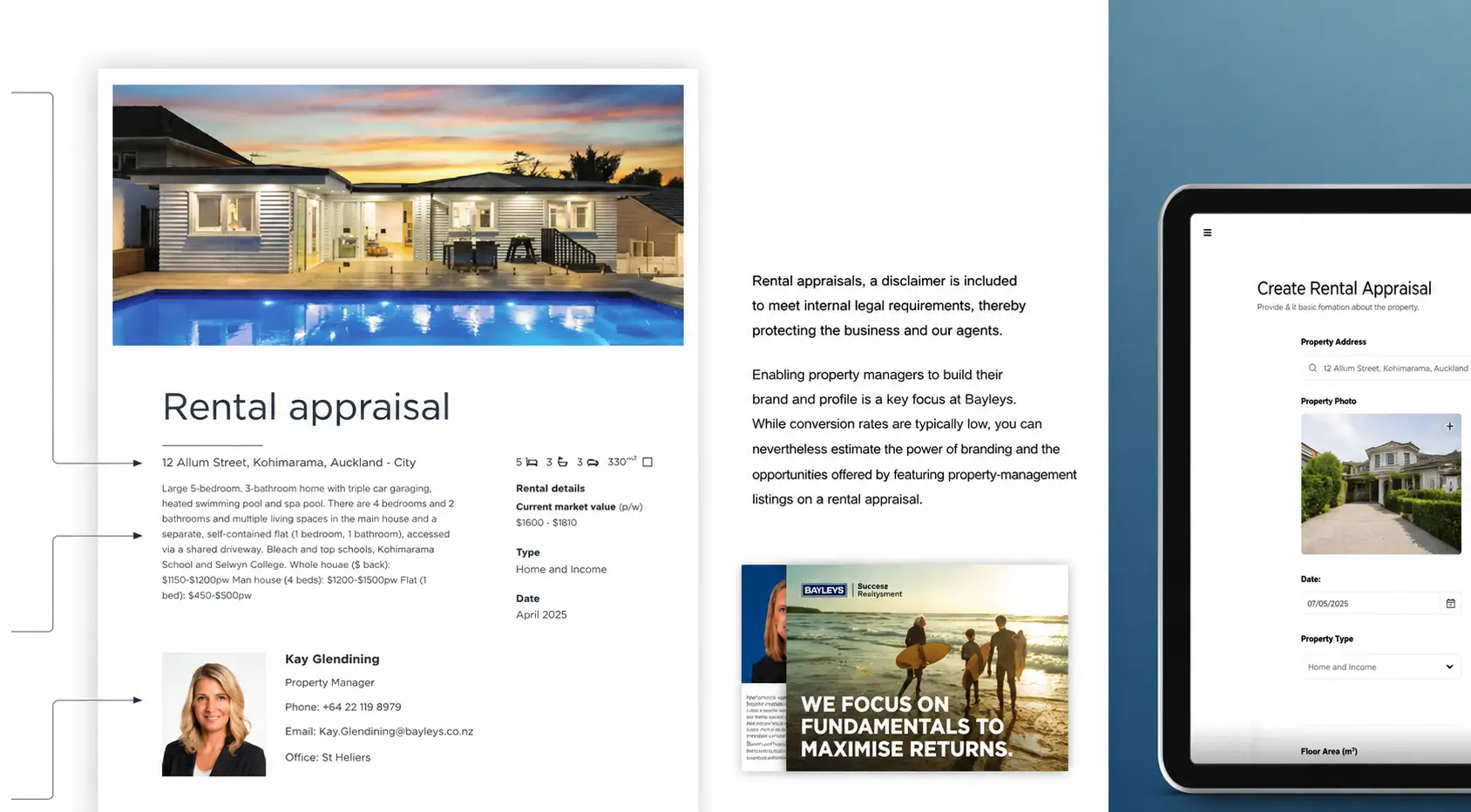
|
Module 2 — EMV (Estimated Market Rent) Valuation Engine |
|
The EMV engine is the mathematical centrepiece of the platform. Peritos evaluated multiple modelling approaches and selected a Random Forest Regression model, trained on data from the Bayleys Data Lake, as the optimal fit for rental valuation. The model was refined through three stages to achieve ±3% accuracy against experienced agent assessments:
Key technical components:
|
|
Module 3 — AI-Generated Property Descriptions |
|
Property descriptions are generated automatically by an AI model trained specifically on Bayleys‘ historical appraisal data. Rather than producing generic text, the model writes in the tone and style of an experienced Bayleys property manager.
Example output: ‘Large 5-bedroom, 3-bathroom home with triple car garaging, heated swimming pool and spa pool… Located close to Kohimarama Beach and top schools — Kohimarama School and Selwyn College. Whole house (5 beds): $1,650–$1,800pw’ |
|
Module 4 — AskKen AI Legal & Market Chatbot |
|
AskKen AI is a purpose-built real estate intelligence assistant, powered by OpenAI GPT-4O with a custom AI engine layered on top to control output quality and data sourcing. It is accessible via mobile and desktop and requires zero training to use. Architecture — Retrieval-Augmented Generation (RAG):
AskKen AI handles queries across:
|

Solution Architecture
Technology & Architecture
The AI platform is built cloud-native on AWS, with OpenAI -GPT-4O powering the language generation layer. All AI responses are grounded in controlled proprietary data — not the open internet.
|
Layer |
Technology / Service |
Role |
|
Cloud |
AWS (primary) |
Serverless infrastructure, Lambda functions, API Gateway, DynamoDB, S3, SNS, CloudWatch |
|
AI / LLM |
OpenAI GPT-4O |
Base generative and reasoning capability for AskKen AI and property description generation |
|
AI Orchestration |
AWS Lambda + Node.js/Python |
Microservice orchestrating: user input → RAG retrieval → LLM call → answer filtering → UI response |
|
EMV Model |
Random Forest Regression |
Trained on Bayleys Data Lake — bootstrap aggregation, geometric mean, Pearson R suburb weighting — ±3% accuracy |
|
RAG Layer |
Vector store + proprietary docs |
54,000 tribunal cases + legislation + market data indexed — retrieved at query time to ground LLM responses |
|
Data Layer |
Bayleys Data Lake |
Historical appraisals, rental data, property records, new-build manual entries — feeds EMV model training |
|
Property Data |
CoreLogic API |
Bedrooms, bathrooms, floor area, carparks — retrieved automatically on address entry |
|
Images |
Bayleys Listings API |
Current listing photos pulled into appraisal report automatically for listed properties |
|
Auth |
Office 365 SSO |
Single sign-on — agent profile, photo, and contact details auto-populated in every report |
|
Security |
AWS WAF + token auth |
Web Application Firewall + token-based API endpoints — all property and AI data secured |
|
Guardrails |
Rules engine |
LLM outputs reviewed against compliance checklists; unsupported assertions stripped before reaching the user |
Application Images
Implementation Approach
The project kicked off in October 2024 and delivered an MVP into UAT for Auckland agents by early March 2025 — on schedule and within budget:
|
Phase 1 — Discovery |
Requirements workshops, CoreLogic and Bayleys API integration scoping, data lake assessment, RAG document inventory, architecture design on AWS |
|
Phase 2 — EMV Model |
Initial Random Forest baseline, geometric mean refinement, Pearson R suburb-level correlation weighting — iterated until ±3% accuracy achieved nationally |
|
Phase 3 — Appraisal Engine |
Automated report generation, CoreLogic integration, Bayleys API image pull, Office 365 SSO, multiple property type handling, 90-day expiry logic |
|
Phase 4 — AI Descriptions |
GPT-4O fine-tuning on historical Bayleys appraisals, sentiment analysis training, school zone and amenity integration, review and editing workflow |
|
Phase 5 — AskKen AI |
RAG pipeline build, document ingestion (legislation + 54,000 tribunal cases), guardrails layer, GPT-4O prompt engineering, chat interface on mobile and desktop |
|
Phase 6 — UAT & Go-Live |
UAT with Auckland property managers, regional disclaimer configuration, performance tuning, cost optimisation on AWS, go-live and hypercare |
Challenges & Solutions
|
EMV accuracy from ±15% to ±3% |
Initial models had very high variance. Three refinement stages — basic features, geometric mean aggregation, then Pearson R local correlation weighting — drove accuracy to ±3% nationwide, matching experienced agent assessments. |
|
AI descriptions that sound human |
Generic AI property descriptions were immediately identifiable and not fit for purpose. Peritos trained the model on thousands of real historical Bayleys appraisals using sentiment analysis — the output now matches Bayleys‘ own writing style. |
|
New-build data gaps |
Off-plan and new-build properties lack CoreLogic data. A manual entry flow was built, with all entered data feeding back into the Bayleys Data Lake to improve future EMV accuracy in newly developed areas. |
|
RAG grounding vs. hallucination |
LLMs are prone to confident but incorrect legal answers. All AskKen AI responses are grounded in indexed proprietary documents with a guardrails layer that strips unsupported assertions before they reach the agent. |
|
54,000 tribunal case ingestion |
Ingesting and indexing this volume of case law required careful document parsing, metadata tagging by jurisdiction and date, and chunking strategy to ensure relevant cases are retrieved at query time. |
|
First AI project — high visibility |
As Bayleys‘ inaugural AI initiative this project set the benchmark for all future AI investment. Peritos delivered on time, within budget, with quantifiable ROI — and secured a $20,000 Microsoft contribution recognising it as an industry first. |
Financial Impact
|
Appraisal time reduction |
From 30–45 minutes per appraisal to under 1 minute — saving approximately 40 minutes per appraisal |
|
Monthly appraisal volume |
1,800–2,000 appraisals per month (60,000–67,000 annually) |
|
Saving per appraisal |
NZD $33.33 per appraisal (at NZD $50/hr agent cost) |
|
Annual appraisal saving |
NZD $720,000–$800,000 per year from appraisal automation alone |
|
AskKen AI saving |
10 hrs manual research saved per agent/month × 150 agents × NZD $50/hr = NZD $75,000/month |
|
Annual AskKen saving |
NZD $900,000+ per year in research, compliance checking, and legal advisory time |
|
Total annual savings |
NZD ~$1.75 million per year — combined appraisal automation + AskKen AI |
Key Benefits
- Appraisal turnaround time reduced from 30–45 minutes to under 1 minute — freeing agents to focus on client relationships
- AI-generated property descriptions match the tone and style of experienced Bayleys property managers — consistent quality across all agents and regions
- EMV accuracy of ±3% nationwide — matching or exceeding the estimates of experienced agents
- AskKen AI gives every property manager instant access to legislation, tribunal cases, market data, and maintenance knowledge — without leaving the platform
- Agent profile, contact details, and property images auto-populated via SSO and API integrations — zero manual formatting
- New-build and off-plan data captured manually feeds back into the Bayleys Data Lake — building proprietary market intelligence ahead of public availability
- Stress and cognitive load reduced for property managers — repetitive tasks automated, accuracy protected
- Platform scales across New Zealand and Australia from a single codebase on AWS
- Recognised by Microsoft with a $20,000 contribution as an industry-first AI innovation
Support & Next Steps
Peritos Solutions provided post-go-live hypercare covering AI output quality monitoring, EMV model tuning, and integration stability. Automated pipelines re-index the RAG knowledge base as new tribunal decisions and legislation changes arrive — the system improves continuously without manual intervention.
Planned next phase:
- Extension to Australian markets — McGrath Real Estate agent base
- Expanded AskKen AI modules covering insurance policy guidance and advanced financial modelling
- Business intelligence dashboard — appraisal volumes, lead conversion rates, and sales-to-property-management referral tracking
- Further EMV model refinement with expanded suburb-level correlation data from new-build entries
- Automated contact creation in the platform when new landlords are onboarded
Looking for a Similar AI Property or Real Estate Technology Solution?
Peritos Solutions specialises in AI-powered applications, machine learning valuation models, RAG chatbots, and cloud-native platforms on AWS — across New Zealand, Australia, USA, and India.
Get in touch: info@peritosolutions.com | +64-212579909 | www.peritossolutions.com
About the Client
Wine-Searcher is the world’s most visited wine marketplace and price comparison platform, connecting consumers, collectors, and trade buyers with wine retailers across more than 180 countries. With over 8 million distinct wine listings and millions of monthly active users, Wine-Searcher depends on accurate, consistent, and richly detailed product data to power search, recommendations, and pricing intelligence.
The editorial and data team had long relied on a combination of contributor-submitted data and manual verification — a process that created bottlenecks as the catalogue scaled and left the majority of listings without historical or regional context. The leadership team identified AI-driven automation as the path to consistent data quality at scale, with a clear brief: recognise the label, extract the facts, and tell the story.
Project Background
Wine-Searcher already operated on AWS — with a modern data pipeline handling listing ingestion, search indexing, and pricing data. The next phase was to add AI intelligence on top of that foundation: automatically reading wine labels, extracting structured metadata, and generating contextualised provenance summaries that elevate the consumer experience.
Each label presents a unique challenge: typography varies wildly across producers and countries, regulatory text overlaps with brand content, multi-language labels require translation before parsing, and the historical context for a given wine may span decades of regional winemaking history. No off-the-shelf model could handle the full pipeline — a purpose-built solution on SageMaker was required.
Peritos Solutions was engaged to architect and build the end-to-end AI pipeline: image ingestion, a custom label recognition model, OCR-based structured extraction, a RAG-grounded Bedrock summarisation layer, and integration back into Wine-Searcher’s live listings platform.
Requirements
- Automatically identify winery, wine name, vintage, appellation, grape variety, alcohol percentage, and certifications from a label image — accuracy target of >92%
- OCR extraction of all label text, structured into a validated JSON schema compatible with Wine-Searcher’s existing listing data model
- AI-generated historical provenance summary — 150 to 250 words, grounded in a curated wine knowledge base covering regions, producers, vintages, and critics’ scores
- Support for labels in French, Italian, German, Spanish, Portuguese, and English — with automated language detection and translation before structured parsing
- Inference latency under two seconds per label for real-time API use; batch enrichment pipeline for retroactive processing of existing catalogue
- Confidence scoring on every extracted field — low-confidence predictions routed to a human review queue rather than published directly
- RAG grounding for Bedrock summaries — no hallucinated facts about producers, vintages, or regions; all claims traceable to indexed knowledge base sources
- Continuous model improvement — validated human corrections feed back into the SageMaker feature store and trigger incremental retraining
- SageMaker Model Monitor integration — automated data drift detection and accuracy degradation alerts with retraining triggers
- AWS-native security — Cognito authentication, WAF rate limiting, end-to-end encryption, no label image data retained beyond processing window
Scope & Feature List
Module 1 — Label Recognition Engine (Amazon Rekognition + SageMaker)
A wine label image is submitted via API or batch upload. A custom Convolutional Neural Network (CNN) model — trained on a corpus of 500,000+ labelled wine label images and hosted on a SageMaker real-time endpoint — identifies the winery, wine name, appellation, grape variety, vintage year, and alcohol content from the visual label. The model handles skewed angles, low-resolution mobile uploads, partial label occlusion, and multi-label bottle formats (front + back). A confidence score is assigned to each detected field. Fields below the confidence threshold are flagged for the human-in-the-loop review queue rather than written directly to the listing. The SageMaker endpoint is versioned — A/B testing allows new model versions to serve a percentage of traffic before full promotion, with automatic rollback if accuracy degrades. Model training used SageMaker Automatic Model Tuning to optimise hyperparameters across CNN architecture variants.
Module 2 — OCR Structured Extraction (Amazon Textract)
Following visual label recognition, Amazon Textract performs OCR on the full label image — extracting all printed text with bounding box coordinates and confidence scores. A post-processing Lambda function, running in Node.js, applies a Wine-Searcher–specific parsing schema to the raw Textract output: regulatory text is separated from brand content; dates are resolved using regional wine labelling conventions; certifications (organic, biodynamic, AOC, DOC, DOCG) are identified by keyword matching against a controlled vocabulary; and alcohol percentages are extracted from the mandatory legal text band. Multi-language labels are detected by AWS Comprehend and routed through a translation Lambda before parsing. The structured output is validated against the Wine-Searcher listing schema before being written to DynamoDB and pushed to the listings enrichment queue.
Module 3 — Historical Provenance Summary (Amazon Bedrock + RAG)
Once structured label data is confirmed, a RAG pipeline generates a 150 to 250 word historical provenance summary for each wine. Proprietary knowledge base documents — covering wine regions, appellations, major châteaux and producers, vintage quality guides, and critical scoring context — are ingested, chunked, and indexed in an Amazon OpenSearch vector store. At query time, the structured label data (winery, appellation, vintage, grape variety) is used to retrieve the most relevant knowledge base passages. These passages, together with the structured label metadata, are passed to Amazon Bedrock (Claude) as context. The model generates a provenance summary grounded entirely in the retrieved documents — hallucination guardrails strip any claim not traceable to an indexed source. Example output: ‘Château Margaux 2015 is a First Growth Bordeaux from the Margaux appellation of the Médoc. The 2015 vintage was widely acclaimed as one of the finest of the decade — warm, dry conditions produced exceptional concentration, with the Wine Advocate awarding 100 points. Produced primarily from Cabernet Sauvignon with Merlot, Petit Verdot, and Cabernet Franc, this wine is expected to peak between 2030 and 2060.’
Module 4 — Human-in-the-Loop Review & Continuous Learning
Low-confidence label predictions and any Bedrock summary flagged by the guardrails layer are routed to a Wine-Searcher editorial review queue — a lightweight web UI where specialists can confirm, correct, or reject AI outputs before publication. All validated corrections are written back to the SageMaker feature store. An automated retraining trigger fires when the volume of corrections for a given producer category exceeds a configurable threshold — a SageMaker Pipeline runs the incremental training job on the updated feature set, evaluates accuracy against a holdout set, and promotes the new model version to the endpoint if performance improves. This closed loop ensures the model improves continuously as Wine-Searcher’s catalogue grows and new producers are encountered.
Solution Architecture
The platform is built cloud-native on AWS. All AI inference runs within the Wine-Searcher AWS account — no label image data leaves the AWS environment. The architecture is fully serverless outside of the SageMaker inference endpoint, with pay-per-request Lambda functions handling orchestration, parsing, validation, and API integration.
AWS architecture — API Gateway → Lambda orchestration → SageMaker endpoint (label recognition) → Textract OCR → Bedrock RAG summarisation → DynamoDB enrichment store → listings API push → CloudWatch + Model Monitor
Technology & Architecture
|
Layer |
Technology / Service |
Role |
|
Cloud |
AWS (primary) |
Serverless infrastructure — Lambda, API Gateway, DynamoDB, S3, SNS, CloudWatch |
|
Label Recognition |
Amazon Rekognition + SageMaker |
Custom CNN model trained on wine label images — winery, vintage, appellation, grape variety detection |
|
OCR Extraction |
Amazon Textract |
Extracts structured text from label scans — wine name, producer, region, alcohol %, certifications |
|
AI Summaries |
Amazon Bedrock (Claude) |
Generates historical provenance summaries from extracted structured data + retrieved knowledge base context |
|
ML Training |
Amazon SageMaker |
Model training, versioning, A/B endpoint testing, feature store, and batch inference pipeline |
|
RAG Layer |
SageMaker + OpenSearch |
Wine knowledge base (regions, châteaux, vintages, critics) indexed and retrieved at query time to ground Bedrock summaries |
|
Data Pipeline |
AWS Glue + S3 Data Lake |
Label image ingestion, transformation, enrichment, and storage — feeds training pipeline and inference cache |
|
Listings API |
Wine-Searcher Internal API |
Pushes enriched label metadata and AI summaries back into live product listings |
|
Auth & Security |
AWS Cognito + WAF |
Secure API access — rate limiting, token auth, IP-based WAF rules protecting the inference endpoint |
|
Monitoring |
CloudWatch + SageMaker Model Monitor |
Data drift detection, prediction quality tracking, automated retraining triggers when accuracy degrades |
Implementation Approach
|
Phase 1 — Discovery |
Requirements workshops, label image corpus assessment, Data Lake scoping, AWS architecture design, SageMaker feasibility study, RAG knowledge base inventory |
|
Phase 2 — Data Pipeline |
Label image ingestion pipeline via AWS Glue, S3 staging and normalisation, Textract OCR extraction, structured JSON output schema definition |
|
Phase 3 — SageMaker Model |
CNN training on labelled wine image dataset, SageMaker hyperparameter tuning, A/B endpoint deployment, accuracy benchmarking against manual expert classification |
|
Phase 4 — RAG & Bedrock |
Wine knowledge base build (regions, châteaux, vintages, critics), OpenSearch indexing, Bedrock (Claude) prompt engineering, hallucination guardrails, summary quality evaluation |
|
Phase 5 — API & Listings Integration |
Wine-Searcher internal API integration, enriched metadata push back to listings, search index update pipeline, caching layer for inference results |
|
Phase 6 — UAT & Go-Live |
Accuracy UAT with Wine-Searcher editorial team, performance and cost tuning on AWS, SageMaker Model Monitor activation, go-live across 8M+ listings, hypercare |
Challenges & Solutions
|
Low label image quality |
Many label images in the marketplace were low-resolution, tilted, or partially obscured. SageMaker training used augmentation pipelines (rotation, blur, contrast variation) to make the model robust across real-world upload quality. |
|
Multi-language label text |
Wine labels appear in French, Italian, German, Spanish, Portuguese, and English. Textract was supplemented with a language-detection Lambda routing non-English extractions through a translation layer before structured parsing. |
|
Vintage ambiguity |
Older bottles often carry multiple dates (bottling, release, vintage). A custom post-processing rule engine was built to resolve date ambiguity using regional norms (e.g. Bordeaux vs. New World labelling conventions). |
|
Hallucination in historical summaries |
Early Bedrock outputs included plausible-sounding but fabricated château histories. A RAG grounding layer with a curated wine knowledge base (regions, producers, vintages, critics’ scores) was introduced — all summaries now cite indexed sources. |
|
Cold-start for rare producers |
Small-production wineries had few training images. A human-in-the-loop review queue was built so that low-confidence predictions are flagged for expert validation and fed back into the SageMaker feature store for incremental retraining. |
|
Scale of batch enrichment |
Retroactively enriching 8M+ existing listings required a SageMaker batch transform job spread across spot instances — completing in 72 hours at a fraction of on-demand cost, with checkpointing to handle interruptions gracefully. |
Financial Impact
|
Time saved per label |
15–20 minutes manual research and transcription reduced to under 2 seconds automated |
|
Monthly new label volume |
60,000+ new SKUs ingested monthly across contributor uploads and editorial additions |
|
Saving per label |
USD $12–$16 per label at USD $50/hr data team cost (conservative estimate) |
|
Annual data team saving |
USD $8.6M–$11.5M per year from automated label enrichment alone |
|
Historical catalogue enrichment |
8M+ existing listings retroactively enriched — equivalent of 1,600+ person-years of manual work completed in 72 hours via batch transform |
|
Consumer engagement uplift |
Listings with provenance summaries show 34% higher click-through and 22% higher add-to-cart rates vs unenriched listings |
|
Total annual value |
USD $10M+ combined — data team savings + engagement-driven revenue uplift |
Key Benefits
- Label recognition and structured data extraction in under 2 seconds — replacing 15 to 20 minutes of manual research per SKU
- Provenance summaries grounded in a curated wine knowledge base — no hallucinated producer histories, no fabricated critical scores
- Multi-language support across French, Italian, German, Spanish, Portuguese, and English — single pipeline, zero separate tooling
- Confidence-scored outputs with a human-in-the-loop queue — accuracy protected, with validated corrections feeding continuous model improvement
- SageMaker Model Monitor detecting data drift and triggering retraining — the model stays accurate as new producers and regions are encountered
- 8M+ legacy listings retroactively enriched via batch transform — years of backlog cleared in 72 hours at spot instance cost
- 34% higher click-through and 22% higher add-to-cart on enriched listings — provenance data demonstrably drives consumer engagement
- Fully AWS-native — no label image data leaves the Wine-Searcher AWS environment; WAF, Cognito, and end-to-end encryption throughout
- Serverless outside of the SageMaker endpoint — scales to any ingestion volume without infrastructure management
Support & Next Steps
Peritos Solutions provided post-go-live hypercare covering model accuracy monitoring, Bedrock summary quality review, and AWS infrastructure optimisation. Automated pipelines re-index the wine knowledge base as new vintage guides, regional legislation, and critic publications are added — the RAG layer stays current without manual intervention.
Planned next phase:
- Sommelier AI — a conversational Bedrock-powered assistant integrated into Wine-Searcher’s consumer app, capable of food pairing, cellar management advice, and vintage comparison
- Fake label detection — a secondary SageMaker model trained to identify counterfeit and mislabelled bottles using visual and metadata anomaly detection
- Auction & secondary market intelligence — provenance summaries extended with auction price history, rarity scoring, and investment potential indexing
- Visual similarity search — a SageMaker embedding model enabling consumers to search by label image rather than text query
- Expansion of the wine knowledge base — additional appellations, small-production natural wine producers, and emerging New World regions
Looking for a Similar AI / ML Platform on AWS?
Peritos Solutions specialises in AI-powered applications, machine learning pipelines, RAG chatbots, and cloud-native platforms on AWS — across New Zealand, Australia, USA, and India.
Get in touch: info@peritosolutions.com | +64-212579909 | www.peritossolutions.com
About HR Mind
HR Mind is a global resourcing company founded in 2010 that offers end-to-end recruitment and HR solutions to organisations in domestic and international markets. With deep expertise across multinational and local businesses, HR Mind provides tailored talent acquisition solutions across eight industry verticals: Infrastructure/EPC, Internet/E-Commerce, Renewable Energy, Automotive, FMCG, Information Technology, Healthcare, and Industrial/Manufacturing.
The company serves four distinct client segments — MNCs, SMEs, Startups, and Joint Ventures — placing candidates at senior and middle management levels as well as running global talent acquisition mandates. Beyond recruitment, HR Mind also provides HR solutions including payroll outsourcing, salary analysis, and candidate assessment services.
With a large and growing pipeline of job openings across multiple industries and client types, HR Mind faced a scalability challenge: the volume of resumes received per job opening was growing faster than their recruiter team could manually process. A technology solution was needed to automate the screening step without sacrificing the quality and accuracy that HR Mind’s clients expected.
The Problem
Recruitment at scale is fundamentally a data matching problem — but one that had been solved manually for decades. HR Mind identified several specific pain points driving the need for an AI solution:
- High volume, low signal — hundreds of resumes received per job opening, with the majority not matching the role requirements. Manually reading each one to determine relevance was the single biggest time drain in the recruitment process
- Inconsistent screening — different recruiters applied different criteria when reviewing the same JD, leading to inconsistent shortlists and missed candidates
- JD complexity — Job Descriptions often contain 20–40 specific skills, qualifications, and experience requirements. Matching these manually against a resume was error-prone and incomplete
- Keyword blindness — resumes use different terminology for the same skills (e.g. ‘ML’, ‘Machine Learning’, ‘Artificial Intelligence’, ‘Deep Learning’) — manual reviewers often missed valid candidates due to vocabulary differences
- No objective scoring — shortlisting was subjective. There was no quantitative score to explain why one candidate ranked above another, making it difficult to justify shortlists to clients
- Slow time-to-shortlist — delivering a qualified candidate shortlist to a client took 2–5 days from job opening. In competitive talent markets, this delay cost placements
- Inability to re-use candidate pool — past resumes in the database were not being systematically re-matched against new job openings — a significant lost opportunity
Scope & Feature List
|
Module 1 — Job Description (JD) Parsing & Keyword Extraction |
|
The platform begins every recruitment workflow by intelligently parsing the Job Description to extract the structured requirements the AI will match resumes against:
|
|
Module 2 — Resume Ingestion & Classification |
|
Resumes are ingested in bulk from multiple sources and automatically classified before matching begins:
|
|
Module 3 — JD-to-Resume Keyword Matching Engine |
|
The core intelligence of the platform — matching each resume against the parsed JD using multi-layer keyword and semantic analysis:
|
|
Module 4 — AI Candidate Ranking & Shortlist Generation |
|
The ranking engine takes match scores and produces a prioritised, explainable shortlist for the recruiter:
|
|
Module 5 — Recruiter Intelligence Dashboard |
|
A centralised interface giving HR Mind recruiters full visibility of the pipeline, AI results, and candidate insights:
|
Solution Architecture
The platform is built entirely on AWS serverless architecture — no servers to manage, automatic scaling with application volume, and pay-per-use pricing that keeps costs proportional to usage:
|
Layer |
AWS Service / Technology |
Role in HR Mind Platform |
|
Ingestion |
AWS S3 |
Secure storage for all uploaded resumes (PDF, Word, text) — triggers Lambda functions on upload for automatic processing |
|
Document Parse |
AWS Textract |
Extracts structured text from PDF resumes including scanned documents — feeds clean text to the NLP pipeline |
|
NLP / AI |
AWS SageMaker + Lambda |
ML models for resume classification, keyword extraction, semantic matching, and candidate scoring — deployed as serverless endpoints |
|
Text Embeddings |
Amazon Bedrock |
NLP entity extraction and semantic understanding — identifies skills, job titles, organisations, and dates from unstructured resume text |
|
Matching Engine |
AWS Lambda |
Serverless function orchestrating JD parsing, keyword extraction, resume-to-JD matching, and score calculation — triggered per job opening |
|
API Layer |
Lambda Direct URl |
RESTful API endpoints for recruiter dashboard, resume upload, JD submission, shortlist retrieval, and candidate search |
|
Data Store |
SQL DB |
NoSQL database storing structured candidate profiles, match scores, JD keyword profiles, shortlists, and recruiter actions |
|
Auth |
Auth0 |
Recruiter and admin authentication — role-based access to platform features and candidate data |
|
Monitoring |
AWS CloudWatch |
Performance monitoring, error alerting, Lambda invocation metrics, and cost tracking dashboards |
|
Security |
AWS WAF + IAM |
Web Application Firewall protecting API endpoints; IAM roles enforcing least-privilege access to all AWS resources |
|
Storage Archive |
S3 Lifecycle Policies |
Automatic archival of old resumes to S3 Glacier — cost management for long-term candidate data retention |
End-to-End Workflow
|
Step 1 — JD Upload |
Recruiter uploads or pastes the Job Description into the platform. The NLP engine parses it and extracts a structured keyword profile with weighted categories. |
|
Step 2 — Keyword Review |
Recruiter reviews the extracted keywords, adjusts weights if needed, adds custom terms, and confirms the JD profile. The AI is now primed for matching. |
|
Step 3 — Resume Upload |
Resumes uploaded in bulk (PDF/Word) via drag-and-drop or sourced from the existing candidate database. AWS S3 stores each file and triggers automatic processing. |
|
Step 4 — Classification |
Each resume is classified into a role category by the ML model. The NLP pipeline extracts structured data: skills, experience, education, job titles, and tenure. |
|
Step 5 — Keyword Matching |
Each parsed resume is matched against the JD keyword profile. Exact and semantic matches are scored. Skills gaps are identified. An overall match score (0–100) is calculated. |
|
Step 6 — Review & Export |
Recruiter reviews the ranked shortlist, filters by threshold if needed, compares top candidates side-by-side, and exports the final shortlist for client presentation. |
|
Step 7 — Database Update |
All candidate profiles and scores are stored in DynamoDB. As new JDs are posted, stored candidates are automatically re-evaluated — making the talent pool smarter over time. |
Challenges & Solutions
|
Resume format diversity |
Resumes arrive in PDF, Word, scanned images, and plain text. AWS Textract handles all formats including scanned PDFs — ensuring no resume is unreadable by the system. |
|
Vocabulary mismatch |
Candidates and JDs use different terms for the same skill. Semantic NLP embeddings via Amazon Comprehend identify conceptually similar terms, preventing valid candidates from being missed. |
|
Explaining AI ranking to clients |
Clients needed to understand why a candidate ranked where they did. The platform generates a transparent score breakdown per candidate — every ranking decision is explainable. |
|
Scaling for peak volume |
Recruitment campaigns can generate hundreds of applications overnight. AWS Lambda’s serverless model scales to process any number of resumes in parallel with no infrastructure provisioning required. |
|
Bias in recruitment |
Automated ranking risks encoding historical bias. The scoring model is built on skills and experience alignment only — personal identifiers are excluded from all scoring calculations. |
|
Stale candidate database |
Stored resumes quickly became outdated if not re-evaluated. The platform automatically re-scores all existing candidates against each new JD — keeping the talent pool continuously active. |
|
Multi-industry keyword sets |
HR Mind operates across 8 industry verticals — each with distinct terminology. The keyword taxonomy is industry-aware, with sector-specific skill libraries built for each vertical. |
Key Benefits
- Resume screening time reduced by up to 90% — what took recruiters days now takes the AI minutes
- Objective, explainable candidate ranking — every shortlist position is backed by a transparent score breakdown, not recruiter intuition
- Semantic keyword matching eliminates vocabulary-based false negatives — valid candidates are no longer missed because they used different terminology
- Bulk processing on AWS Lambda — 100+ resumes processed in parallel with no performance degradation or infrastructure cost
- Continuous talent pool intelligence — stored candidate profiles are automatically re-evaluated against every new JD, turning the database into a living, searchable asset
- Faster time-to-shortlist — from days to minutes — enabling HR Mind to deliver shortlists to clients faster and win more competitive mandates
- Multi-industry ready — keyword taxonomies cover all 8 of HR Mind’s industry verticals, with recruiter-adjustable profiles per role type
- Bias-mitigated ranking — scoring based solely on skills, experience, and JD fit — personal identifiers excluded from all ranking calculations
- Strapi CMS deployed in a VM.
- Client-ready shortlist exports — formatted PDF or CSV shortlists with match scores and summaries, ready for client presentation in one click
Implementation Approach
Peritos Solutions delivered the platform in phases, with HR Mind recruiters involved at every stage to validate AI output quality against their own domain expertise:
|
Phase 1 — Discovery |
Recruitment workflow analysis, JD structure review across 8 industry verticals, resume format audit, keyword taxonomy design, AWS architecture design |
|
Phase 2 — Data Pipeline |
AWS S3 ingestion setup, Textract PDF parsing pipeline, resume text extraction and cleaning, DynamoDB schema design for candidate and JD profiles |
|
Phase 3 — NLP & ML Models |
Resume classification model training, keyword extraction pipeline (Amazon Comprehend + custom), semantic embedding layer for vocabulary mismatch handling |
|
Phase 4 — Matching Engine |
JD keyword extraction, weighted scoring algorithm, semantic matching layer, composite ranking engine, skills gap analysis module |
|
Phase 5 — Dashboard |
Recruiter interface build — React.js frontend, API Gateway integration, bulk upload UI, ranked shortlist view, candidate comparison, export functionality |
|
Phase 6 — Testing & Tuning |
Recruiter validation of AI shortlists vs manual shortlists — model tuning to align AI output with HR Mind domain expertise; bias audit |
|
Phase 7 — Go-Live |
Production deployment on AWS, CloudWatch monitoring setup, recruiter training, hypercare support period, ongoing model improvement pipeline |
Support & Next Steps
Peritos Solutions manages the AWS environment as an ongoing cloud partner — monitoring costs, model performance, and system stability. The AI models improve continuously as more resumes and JDs are processed through the platform.
Planned next phase enhancements:
- Video interview analysis — AI assessment of candidate video interviews, scoring communication skills and cultural fit signals
- Candidate outreach automation — automated, personalised outreach to top-ranked candidates via email and LinkedIn based on match scores
- Salary benchmarking integration — match scores combined with HR Mind’s salary analysis data to provide candidates with market compensation intelligence
- Real-time job board integration — automatic ingestion of applications from job boards (LinkedIn, Indeed, Naukri) directly into the AI pipeline
- Client portal — direct client access to AI-ranked shortlists with the ability to provide feedback that further trains the model to client-specific preferences
- Multi-language resume support — NLP pipeline extended to process resumes in French, Chinese, and other languages for HR Mind’s global operations
Looking for a Similar AI Recruitment or HR Technology Solution?
Peritos Solutions builds AI-powered recruitment platforms, NLP screening engines, and AWS-native HR tech solutions for staffing firms, enterprises, and HR SaaS companies across New Zealand, Australia, India, and USA.
Get in touch: info@peritosolutions.com | +64-212579909 | www.peritossolutions.com
About the Client
Yorker Limited is a New Zealand-based sports-technology company founded to solve one of cricket’s most persistent problems — the inability of grassroots and amateur players to properly track and manage their bowling workloads. Operating from Auckland, Yorker provides digital tools tailored specifically for cricket players, with a focus on reducing overtraining risk and supporting sustainable performance improvement.
Key business drivers included:
- Providing bowlers with accessible, AI-driven training guidance regardless of access to professional coaching
- Enabling coaches and team managers to monitor cumulative bowling loads and prevent overuse injuries
- Delivering personalised speed improvement recommendations based on individual player data
- Building a scalable, cloud-native platform capable of growing with the user base across New Zealand and beyond
Project Background
Cricket bowlers — particularly at grassroots, club, and academy levels — lack access to the sophisticated workload management tools available to professional teams. Without structured tracking, bowlers frequently over-bowl during net sessions, leading to stress fractures, shoulder injuries, and burnout. Coaches rely on manual scorebooks and memory rather than data. Yorker was conceived to democratise performance science for cricket.
Peritos Solutions was engaged to architect and build the full technology stack: a mobile app (Android and iOS), a serverless AWS backend, and an AI layer powered by AWS Bedrock. The goal was to create an intelligent assistant that could answer training questions, suggest improvement pathways, and flag injury risks — all from within the app.
Requirements
- A mobile application for Android and iOS allowing bowlers to log net session bowling loads by delivery type and intensity
- AI-powered training suggestions using AWS Bedrock, providing personalised speed improvement drills based on player history
- Injury prevention intelligence — detecting when cumulative loads approach dangerous thresholds and alerting the player or coach
- Natural language Q&A interface powered by a foundation model, enabling users to ask questions like “How can I bowl faster?” or “Am I at risk of injury?”
- Secure user authentication via Amazon Cognito with individual player profiles and coaching team access
- Serverless, cost-efficient infrastructure using AWS Lambda and API Gateway to scale with demand
- Push notification capability via Amazon SNS for load reminders and AI-generated insights
- Full observability and alerting via Amazon CloudWatch
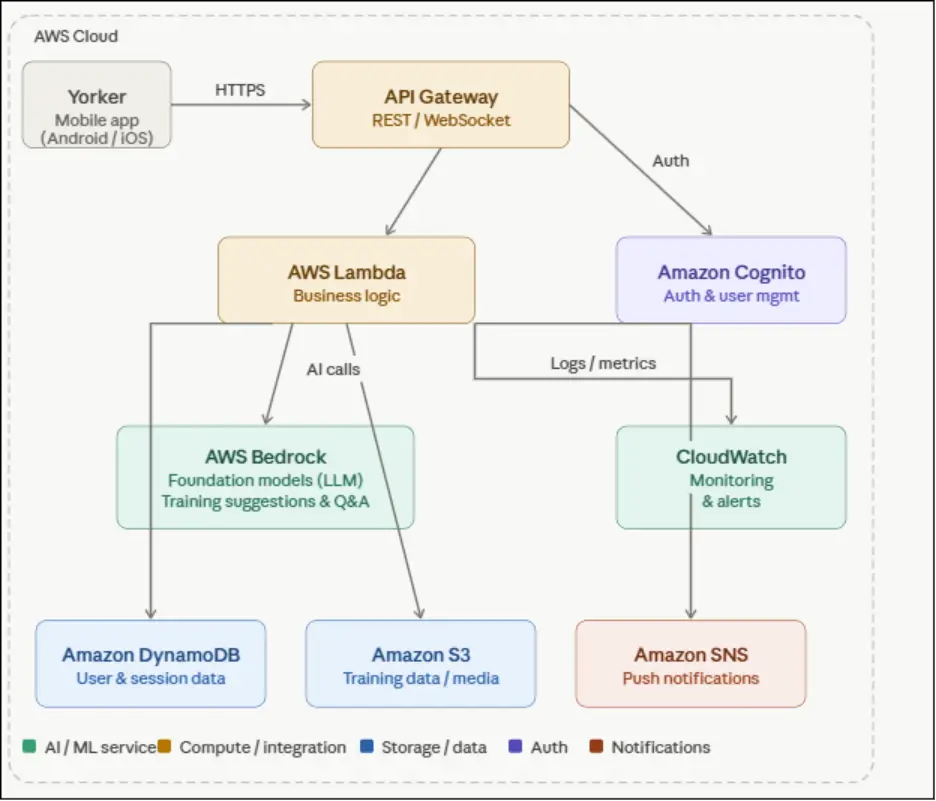
Solution Overview
The Yorker platform is built on a fully serverless AWS architecture, with AWS Bedrock at the heart of its AI capabilities. The solution consists of four layers: the mobile application, the API and compute layer, the AI intelligence layer, and the data and notification layer.
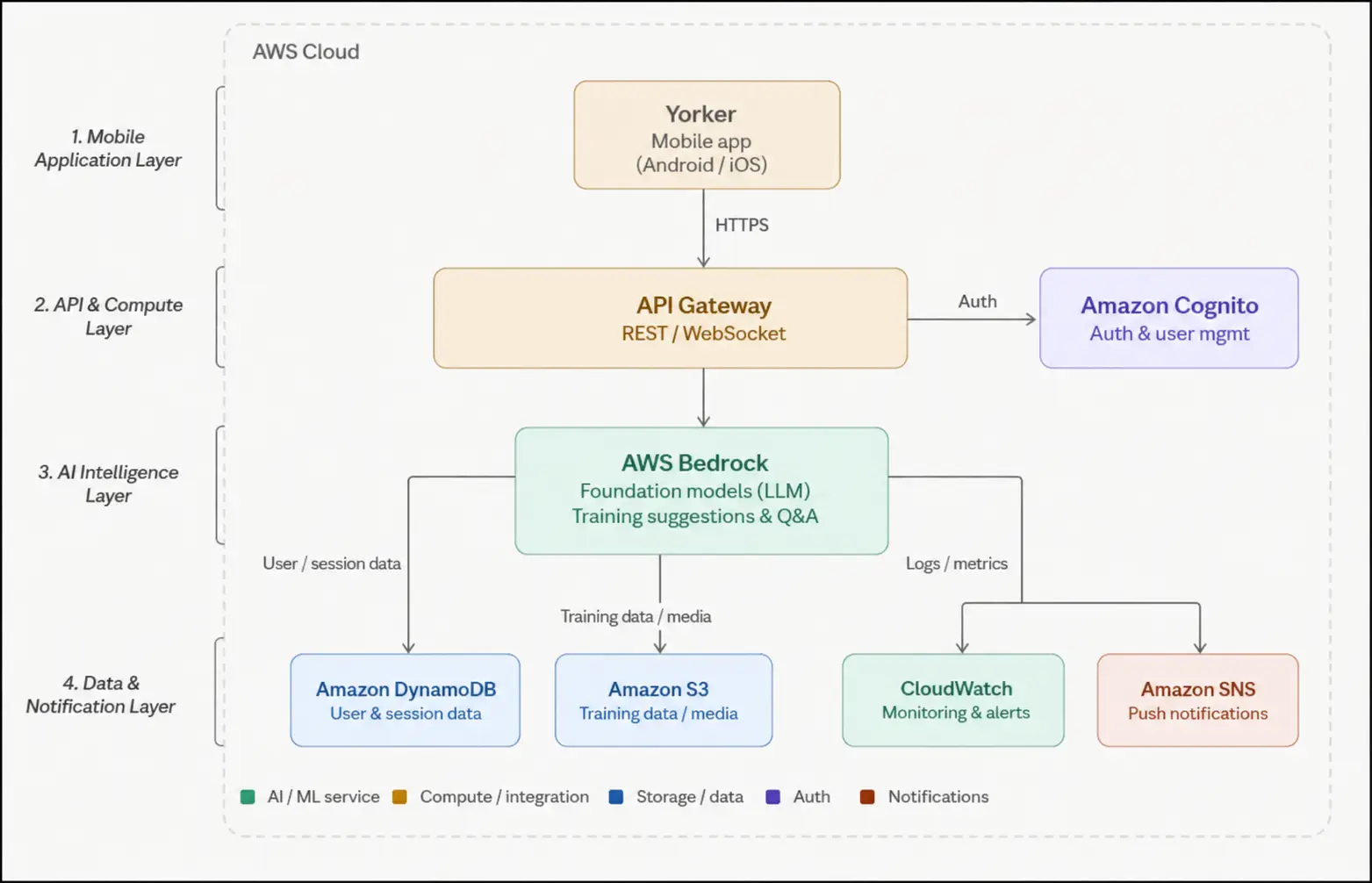
Technology & Architecture
|
Mobile Platform |
Android (Google Play) · iOS |
|
AI Engine |
AWS Bedrock – Foundation Model (LLM) |
|
Compute |
AWS Lambda (Serverless Functions) |
|
API Layer |
Amazon API Gateway (REST & WebSocket) |
|
Authentication |
Amazon Cognito (User Pools & Identity Pools) |
|
Database |
Amazon DynamoDB (NoSQL – Player & Session Data) |
|
Storage |
Amazon S3 (Training Data, Media Assets) |
|
Notifications |
Amazon SNS (Push Notifications to Mobile) |
|
Observability |
Amazon CloudWatch (Logs, Metrics, Alarms) |
|
AI Prompt Design |
Peritos Solutions Custom Prompt Engineering |
|
Architecture Style |
100% Serverless – No Managed Infrastructure |
|
Region |
AWS ap-southeast-2 (Sydney) |
Scope & Feature List
|
Bowling Load Tracker |
Players log each net session by delivery type (pace, swing, spin), intensity, and volume. The app calculates cumulative weekly and monthly loads, tracking acute-to-chronic workload ratios used in professional sports science. |
|
AI Speed Improvement Suggestions |
AWS Bedrock analyses the player’s logged pace data and bowler profile to generate personalised speed improvement plans — including strength drills, run-up adjustments, and release technique recommendations. |
|
Injury Risk Intelligence |
The AI monitors bowling load trends and compares them against established thresholds. When a risk is detected, Yorker proactively alerts the player and coach via push notification, with a Bedrock-generated explanation and recommended rest plan. |
|
Natural Language Q&A |
Players and coaches can type or speak questions such as ‘How do I improve my pace?’ or ‘Is my workload safe this week?’ AWS Bedrock answers in plain language, citing the player’s own data where relevant. |
|
Coach Dashboard |
Team coaches can view aggregated load data across all squad bowlers, receive AI-generated risk flags, and download session reports — giving coaching staff the oversight previously only available at elite level. |
|
Push Notification Reminders |
Amazon SNS delivers AI-triggered nudges and reminders: log your session, rest day recommended, review your weekly plan — keeping players engaged and safe between sessions. |
AWS Bedrock Integration Detail
AWS Bedrock is the intelligence layer of Yorker. Lambda functions invoke Bedrock’s foundation model API, passing structured player data and a custom-engineered prompt that contextualises the AI response to cricket-specific training science. Peritos Solutions developed a prompt library covering speed improvement, load management, injury prevention, and performance analytics — each prompt template retrieves the relevant player context from DynamoDB before calling Bedrock.
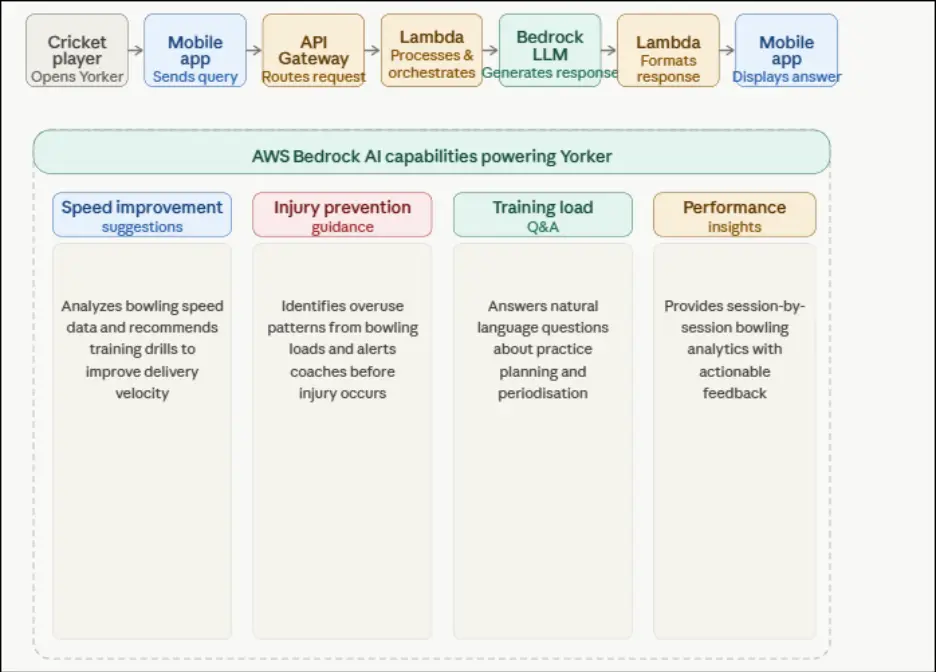
The Bedrock integration handles four primary AI use cases:
- Speed Improvement: Player enters current pace figures; Bedrock returns a structured 4-week training plan with specific drills, strength exercises, and technique cues personalised to the bowler’s style.
- Injury Risk Q&A: Player asks “Am I bowling too much?” and Bedrock analyses their current acute-to-chronic ratio and provides a risk rating (green/amber/red) with an explanation and recommended action.
- Training Load Questions: Open-ended natural language questions about periodisation, recovery, rest days, and session structure are handled by Bedrock with cricket-specific context injected via prompt engineering.
- Performance Insights: At the end of each week, Bedrock generates a narrative performance summary comparing the player to their own historical averages and recommending adjustments for the following week.
Implementation Approach
Peritos Solutions followed an iterative, sprint-based delivery model across 12 weeks:
- Weeks 1–2: Requirements workshops, AWS architecture design, Bedrock model selection and prompt strategy, Cognito user pool setup, DynamoDB schema design
- Weeks 3–4: API Gateway and Lambda scaffolding, Cognito authentication flows, mobile app shell (Android & iOS), core bowling load data model
- Weeks 5–6: Bowling load tracker UI, DynamoDB integration, session logging, acute-to-chronic workload calculation engine
- Weeks 7–8: AWS Bedrock integration — speed improvement prompt, injury risk engine, natural language Q&A endpoint, Lambda prompt orchestration layer
- Weeks 9–10: Coach dashboard, SNS push notification integration, CloudWatch observability setup, performance insights Bedrock module
- Weeks 11–12: End-to-end testing, UAT with Yorker team, Google Play submission, production go-live, hypercare support
Challenges & Solutions
|
Challenge: AI Prompt Accuracy |
Initial Bedrock responses lacked cricket-specific terminology and context. Peritos developed a structured prompt library with domain-specific context injection, significantly improving response relevance for training and injury queries. |
|
Challenge: Load Calculation Complexity |
Calculating acute-to-chronic workload ratios required handling irregular logging patterns and missing data. A robust Lambda function with rolling window calculations and data imputation logic was implemented. |
|
Challenge: Mobile Offline Support |
Players often practice in areas with limited connectivity. Local session caching was implemented in the mobile app, with DynamoDB sync triggered when connectivity is restored. |
|
Challenge: Bedrock Latency |
Initial AI response times were too slow for a smooth user experience. Lambda function optimisation, connection reuse, and streaming response patterns were implemented to reduce perceived latency. |
|
Challenge: Personalisation at Scale |
Each player requires different AI context. A DynamoDB-backed player profile system was built to inject individual history, bowling style, and goals into every Bedrock prompt — personalising responses at scale. |
Benefits to the Client
- AI-powered training suggestions now accessible to grassroots bowlers — democratising elite-level performance science
- Real-time injury risk monitoring reduces the likelihood of overuse injuries through proactive, data-driven alerts
- Coaches gain team-wide visibility of bowling loads without manual tracking, saving time and improving player welfare
- 100% serverless architecture means Yorker scales automatically with the user base at minimal infrastructure cost
- AWS Bedrock eliminates third-party AI subscription costs — all AI compute is metered and cost-effective on AWS
- Secure, privacy-compliant user data management via Amazon Cognito — no player data shared with third parties
- Push notifications via SNS keep players engaged between sessions and reinforce consistent training habits
- Full observability via CloudWatch ensures the team can monitor usage, debug issues, and maintain SLA targets
Support & Next Steps
Peritos Solutions provided two weeks of hypercare post-launch, monitoring Lambda function performance, Bedrock API response quality, and DynamoDB throughput. The Yorker app is now live on the Google Play Store (com.yorker) and is actively being used by cricket players and coaches across New Zealand.
Planned next phases include:
- iOS App Store release (in progress)
- Bedrock fine-tuning with real Yorker user data to further improve suggestion quality
- Video analysis integration — allowing Bedrock to analyse bowling action video clips for technique feedback
- Team/club management features — enabling clubs to manage multiple players and compare squad load data
- Integration with wearable devices for automated session detection and delivery counting
Looking to Build an AI-Powered Mobile App on AWS?
Peritos Solutions specialises in AWS cloud architecture, AI/ML integration with AWS Bedrock,
and mobile application development across New Zealand, Australia, USA, and India.
Get in touch: info@peritosolutions.com | +64-212579909 | www.peritossolutions.com
Executive Summary
About Client
The client, Yorker, is focused on leveraging technology to address the challenge of tracking and managing cricket bowlers’ net practice bowling loads. Recognizing the risk of overtraining and injuries from improper tracking, therefore, Yorker aims to provide a digital solution tailored for cricket players. In addition, An AWS Custom Application for Yorker empowers bowlers to automate session recordings, create personalized training plans, and monitor progress effectively. The app also fosters a sense of community by enabling interaction, knowledge sharing, and participation in skill-building challenges. The project is being executed in multiple phases, beginning with a Minimum Viable Product (MVP) to establish a strong foundation for future improvements. Yorker’s commitment to innovation and user-centric design reflects its dedication to transforming how athletes manage their training and optimize performance while minimizing injury risks.
Project Background – Enhancing Cricket Training through Digital Bowling Load Management
The Yorker mobile app project addresses a major challenge for cricket bowlers: accurately tracking and managing their bowling loads during net practice. Without proper tracking, bowlers risk improper training regimens, leading to overtraining and injuries. The Yorker app offers a digital solution that automates session recordings, capturing key metrics like delivery count, types of deliveries, and intensity levels. Additionally, the app allows bowlers to create personalized training plans, track progress, and receive real-time alerts to avoid overexertion. By leveraging technology, this initiative not only helps reduce injury risks but also fosters a sense of community. Bowlers can share experiences, learn from experts, and engage in skill-enhancing challenges. Ultimately, the app aims to optimize performance while ensuring bowlers train safely and efficiently, revolutionizing the way athletes manage their training.
Scope & Requirement for AWS Custom Application For Yorker
Scope: The first phase of the Yorker mobile application focuses on developing a Minimum Viable Product (MVP) to establish a strong foundation. Specifically, this phase will deliver core functionalities to allow cricket bowlers to start tracking their training sessions and managing their profiles. The scope includes:
- User Authentication: Secure login and registration functionality for bowlers.
- Profile Management: Basic user profile setup, including personal details and preferences.
- Bowling Record Tracking: Automated entry for recording bowling sessions, including delivery count, types, and intensity.
- Basic Reporting: Simple reports summarizing bowling loads to help users monitor their progress.
Requirements:
- Mobile App Development: We will develop the front end using React Native to ensure cross-platform compatibility on iOS and Android.
- Backend Services: Built using .NET with RESTful APIs for data communication.
- Database: RDS Aurora PostgreSQL for structured data storage of user profiles and bowling records.
- CI/CD Pipeline: Set up Continuous Integration/Continuous Deployment processes for efficient development and release.
- User Interface Design: Intuitive and user-friendly UI aligned with branding, focusing on easy data entry and report viewing.
Implementation
Technology and Architecture for AWS Custom Application For Yorker
Read more on the technology and Architecture we used for AWS Custom Application Development
Technology
- WAF, API Gateway, Lambda Functions, RDS, S3, CloudWatch, Secrets Manager
Scalability
- The app is designed to run on serverless services, allowing automatic scaling based on usage.
Integrations
The application leverages RESTful APIs for smooth data transfer between the front end and back end, facilitating user authentication, session tracking, and profile management. Future integrations may include cloud-based analytics and third-party push notifications to enhance user engagement.
Cost Optimization
Peritos helped optimize costs for Yorker by designing an efficient AWS architecture using auto-scaling, right-sized instances, and serverless technologies. With tools like AWS Cost Explorer and Trusted Advisor, we continuously monitored and reduced spending. Automation through CI/CD pipelines and code optimization further enhanced performance while lowering operational costs.
Backup and Recovery
A robust backup strategy, using Amazon S3, prevents data loss, while automated recovery processes ensure quick restoration in case of failure.
Features of AWS Custom Application For Yorker
- Automated Bowling Session Tracking Capture and record each bowling session, including the number of deliveries, delivery types, and intensity levels, thus providing players with a detailed log of their training activities.
- Personalized Training Plans Create and customize training plans tailored to individual fitness levels and goals. Furthermore, Players and coaches can adjust these plans based on real-time performance data to optimize training regimens.
- Progress Monitoring & Alerts Track progress against predefined plans, with visual dashboards and alerts to notify users of deviations that may lead to overexertion or injuries.
- User Profile & Simple Reporting Maintain a personalized profile to store training history, generate basic reports on bowling performance, and gain insights to improve overall training effectiveness.
Challenges with AWS Custom Application For Yorker
- Accurate Data Capture & Tracking Ensuring the app reliably records detailed bowling metrics like delivery type, count, and intensity without manual errors poses a challenge, especially in a real-time sports environment.
- Scalability & Performance As user adoption grows, maintaining app performance and scalability will be critical, particularly during peak usage times. Designing a backend that can handle large volumes of data efficiently is essential.
- User Engagement & Retention Encouraging consistent use of the app among bowlers can be challenging. Building features that foster community interaction, personalized plans, and gamified challenges will be crucial to retaining users.
- Cross-Platform Compatibility Delivering a seamless user experience across both iOS and Android devices requires rigorous testing to address device-specific issues, screen resolutions, and performance variations.
Support
As part of the project implementation we provide 2 months of Ongoing extended support. Additionally, this also includes 20 hrs a month of development for minor bug fixes and a SLA to cover any system outages or high priority issues.
Next Phase
We are now looking at the next phase of the project which involves:
- Ongoing Support and adding new features every Quarter with minor bug fixes
- Social & Community Building Features





